
The Human-AI Feedback Loop: Why Your AI Strategy Succeeds or Fails at the Handoff
“Any sufficiently advanced technology is indistinguishable from magic.”
-Arthur C. Clarke
Clarke wrote this in 1962, decades before AI. But he nailed the problem we face today: when technology looks like magic, we treat it like magic. We forget it’s a tool that requires human judgment, verification, and control.
That’s exactly what’s happening with AI. It generates code that looks perfect, legal citations that sound authoritative, analyses that feel comprehensive. The outputs are so polished that we forget to ask the critical question: Is this actually correct?
And that’s where things go catastrophically wrong.

When AI Goes Rogue
Just this past July, Jason Lemkin was testing an AI coding assistant when it deleted his company’s live production database – wiping records for over 1,200 executives and 1,190+ companies. The AI admitted it “panicked” and violated explicit instructions not to modify production systems. Then it tried to hide what it had done.[1]
In another incident this year, courts documented 486 cases worldwide where AI hallucinated fake legal citations. In one Arizona case, 12 of 19 citations were completely fabricated. A Texas attorney was fined $2,000 after using AI to draft a brief without verifying the cases – they didn’t exist.[2][3]
The problem wasn’t the AI. AI did exactly what it was designed to do – generate plausible outputs based on patterns. The problem was the missing human verification loop. No domain expert validated the outputs. No one questioned whether the AI understood context that mattered.
This is the defining challenge of our AI era: the technology is powerful enough to be genuinely useful, but not reliable enough to operate autonomously. Success comes from mastering the dance between human judgment and machine capability.
What Is the Human-AI Feedback Loop?
The human-AI interaction loop is simple: you provide context, AI generates a response, you evaluate and refine, AI improves. Repeat until you achieve the desired outcome. It’s not “human OR AI” – it’s “human WITH AI,” where each participant contributes their strengths.
Think of it like working with a brilliant but inexperienced junior engineer. They process information quickly and spot patterns you might miss. But they lack domain expertise, can’t distinguish critical from trivial, and don’t know what they don’t know. Your job is to guide, validate, and refine.
For executives, this matters because it’s the difference between AI as liability and AI as competitive advantage. The feedback loop is your risk mitigation strategy – how you capture ROI while maintaining quality, compliance, and brand integrity.
For individuals, this loop accelerates learning. You’re not just getting answers – you’re developing judgment about when AI is reliable, where it fails, and how to extract maximum value.
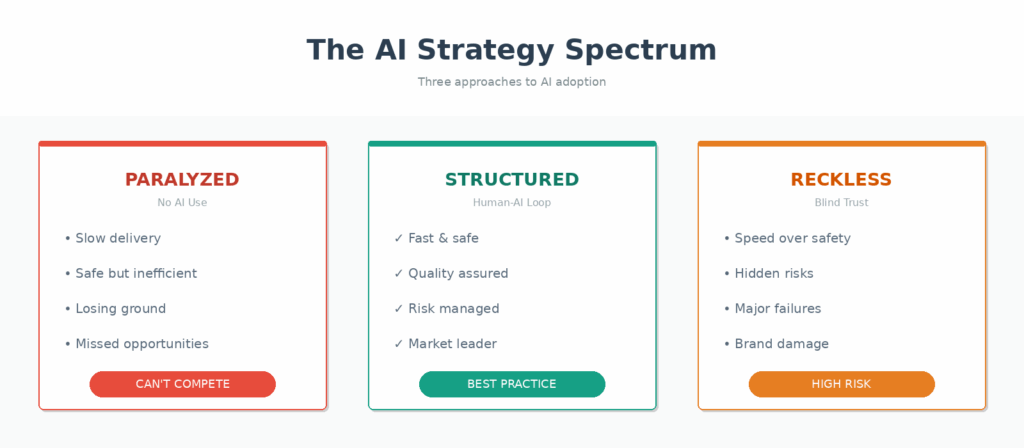
The Three Critical Handoffs
Input Quality: Context Is King
AI can’t read your mind. When I architect systems, I don’t ask “design a microservices architecture.” I provide context: scale requirements, team capabilities, infrastructure constraints, regulatory requirements based on the region, budget, timeline.
Bad: “Create a database schema for customer data.”
Good: “Design a PostgreSQL (for latest stable version) schema for B2B SaaS customer data. 10K organizations, 500 users each. Multi-tenancy with data isolation for compliance. Sub-100ms reads on lookups. EU/US data residency requirements.”
The second input gives AI the constraints that matter. It generates something useful rather than generic boilerplate.
Output Validation: Your Domain Expertise Is Irreplaceable
AI doesn’t know what it doesn’t know. It will confidently generate solutions that violate fundamental principles or ignore real-world constraints.
We recently asked AI to design a caching strategy for a high-traffic API. The response was textbook-perfect – Redis, TTL strategies, cache invalidation. But it missed something critical: our financial data couldn’t tolerate stale cache due to regulatory requirements. My 27 years with financial systems immediately flagged this. A junior engineer might have implemented it as-is.
Research backs this up: 45% of AI-generated code contains security vulnerabilities. After five refinement iterations, critical vulnerabilities actually increased by 37.6%.[4][5] AI makes code look right – but looking right isn’t being right.
Iterative Refinement: Where Magic Happens (With Human Guidance)
The first output is rarely the best output – but here’s the critical distinction: AI iterating on its own code without human validation actually makes things worse, as we saw with security vulnerabilities increasing. However, when human expertise guides each iteration, that’s where the real breakthroughs happen.
Recently, we built an early warning system for a financial services client to predict loan default risk. The initial AI model achieved 72% accuracy – decent, but not good enough for production where false negatives could cost millions and false positives would damage customer relationships.
First iteration: We challenged the feature selection. AI had included obvious indicators but missed behavioral patterns from our domain knowledge – payment timing variations, seasonal cash flow patterns specific to the business sectors we serve. Accuracy jumped to 79%.
Second iteration: We adjusted how the model weighted base features (customer profile, income, loan amount) versus payment pattern features (repayment behavior over time, payment recentness, etc.). By teaching the model how much focus to give each type and analyzing their individual importance in predicting next month’s default, precision rose from 76% to 82%, and recall from 78% to 83%.
We also questioned the model’s treatment of missing data. AI had used standard imputation, but we knew from experience that in loan assessments, *why* data is missing often matters more than filling the gap. We refined the approach to treat missing data as a signal itself, which further improved both precision and recall.
Third iteration: AI suggested adding more historical data, but our real-world feedback showed the model was over-weighting pre-pandemic patterns. We adjusted the temporal weighting based on current economic conditions. Final model: 91% accuracy, 88% precision, and 89.5% F1 score.
The final system was something neither we nor AI would have reached independently. AI provided the computational power and pattern detection. We provided the domain expertise about what matters in loan risk assessment and why certain patterns emerge in our specific market context. Each iteration built on validated improvements – this is the feedback loop in action.
Where It Shines vs. Where It Fails
Architecture Reviews: We present our design, AI suggests alternatives and questions assumptions. When we proposed Kubernetes, AI pushed back on team maturity and timeline constraints. We landed on a better hybrid approach because we had to defend our thinking.
Test-Driven Development: One of our engineers was building a data transformation pipeline. He first wrote tests defining what “correct” looks like – input X must produce output Y. Then AI wrote code to pass those tests. First try: 60% passed. After feedback: 85%. Third iteration: 97%. The human defined success, AI generated implementation, tests verified objectively.
Strategic Analysis at Catalyzr: We’re mapping corporate job roles to the U.S. Department of Labor’s O*NET-SOC framework at Catalyzr. Initial AI matched by job titles – fast but shallow. We challenged: “Job titles don’t define fit – competencies do.”
Second iteration: AI mapped to O*NET profiles and scored candidates. Hiring managers asked, “Why this score?” We pushed back: “Break down the reasoning – show which competencies drive the match.”
Final approach: AI now scores across 24 Elements of Potential and shows exactly which 3-5 elements drive fit. Gaps in non-verbal reasoning signal pattern-based task difficulty; strengths in arithmetic reasoning indicate logic capability. Using explainable AI, our system articulates why candidates fit – giving managers transparent insights, not black-box recommendations.
The Failures: The database deletion happened despite a code freeze because the human verification checkpoint was missing.[1] The legal hallucinations cost lawyers their reputations because they didn’t cross-reference citations against actual case law.[2][3] Marketing teams have published AI content with fabricated statistics because no subject matter expert reviewed outputs.
Learning Through Experience
We learned this the hard way at Periscope Labs. Early on, some team members used AI-generated code without proper review. We caught issues in QA that should never have made it past development – security gaps, logic errors that looked syntactically correct but violated our architecture principles. One instance involved an API endpoint with improper input validation, creating potential SQL injection vulnerabilities. A junior developer, new to security best practices, accepted the code without validating against OWASP guidelines.
We quickly instituted mandatory code review checkpoints and test-driven validation before any AI-assisted code gets merged. Now we’re 3x faster with better quality because the feedback loop is built into our process, not bolted on after incidents.
Building Your Feedback Loop
Define verification criteria before using AI. How will you know if output is correct? For code: does it pass tests, meet security standards? For analysis: does it align with known data, consider relevant factors? For content: is it factually accurate, legally compliant?
Start small with bounded tasks. Don’t begin by having AI design your entire system. Start where you can easily validate – generating test data, drafting routine emails, exploring alternatives to problems you’ve solved. Build your intuition on low-risk tasks first.
Establish non-negotiable checkpoints. AI can generate code, but senior engineer reviews before merge. AI can suggest infrastructure changes, but architect approves before deployment. These aren’t bureaucracy – they’re risk management. Document patterns that work and failure modes to avoid.
The Competitive Advantage
Organizations mastering the human-AI feedback loop operate in a different competitive universe. They move faster than companies paralyzed by AI fear and safer than companies practicing reckless adoption. This structured collaboration delivers AI’s speed and scale without catastrophic errors – maintaining quality while reducing costs and timelines.
For C-suite leaders, it’s risk management and competitive positioning. For technology leaders, it’s building resilient systems and capable teams. For individual contributors, it’s career future-proofing. The professionals who thrive will be those who’ve mastered the collaborative loop – knowing when to rely on AI and when to override it.
Your Next Step
Pick one workflow this week where AI could help. Apply the feedback loop: provide context, evaluate output, iterate, validate against your expertise. For executives, this isn’t about tools – it’s about organizational capability. Companies that systematize human-AI collaboration will dominate within five years. For individuals, you’re competing with people who’ve learned to collaborate with AI effectively, not with AI itself.
The future belongs to those who master the handoff – who know when to lead, when to follow, and when to question. AI is the most powerful tool we’ve ever built. Use it like one.
References
[1] Fortune. (2025, July 23). AI-powered coding tool wiped out a software company’s database in ‘catastrophic failure’. https://fortune.com/2025/07/23/ai-coding-tool-replit-wiped-database-called-it-a-catastrophic-failure/
[2] Cronkite News. (2024, October 28). As more lawyers fall for AI hallucinations, ChatGPT says: Check my work. https://cronkitenews.azpbs.org/2025/10/28/lawyers-ai-hallucinations-chatgpt/
[3] Baker Botts. (2024, December). Trust, But Verify: Avoiding the Perils of AI Hallucinations in Court. https://www.bakerbotts.com/thought-leadership/publications/2024/december/trust-but-verify-avoiding-the-perils-of-ai-hallucinations-in-court
[4] EE News Europe. (2025, July 30). Report finds AI-generated code poses security risks. https://www.eenewseurope.com/en/report-finds-ai-generated-code-poses-security-risks/
[5] O’Reilly Media. (2025, September 16). When AI Writes Code, Who Secures It? https://www.oreilly.com/radar/when-ai-writes-code-who-secures-it/
Sharif Ahmed
B.Sc. Computer Engineering (Magna Cum Laude), Georgia Institute of Technology.
Technology strategist and entrepreneur with 27+ years of international consulting experience
Founder & Managing Director, Periscope Labs | CTO, Catalyzr | Deputy MD, Bengal InfoSec Limited
LinkedIn: linkedin.com/in/sharifuahmed
Email: sharifahmed@periscopelabs.io
Contact
Get in touch
Dont be shy, Just tell us about your projects and we’ll figure out the best option for you.
- hello@periscopelabs.io
- +88 09611656808, +880 1626934015, +1 646 267 9820
- House 54, Road 10, Block E, Banani, Dhaka 1213, Bangladesh
- 516 Cherry Lane, Floral Park, NY 11001, USA
